 Github Code: Unfinishedgod
Github Code: Unfinishedgod
Titanic 링크: Titanic Data
영화: 타이타닉



분석을 하기전에 당시의 시대 상황이 어떤지 파악해보자. 영화 타이타닉의 장면들을 가져와봤다. 장면들에서 볼수 있겠지만 우선 객실의 등급이 우선시 되는 시대였다. 1,2,3등급의 객실로 사람을 구분 짓고 보트에 탑승 할때도 되도록이면 1등급의 사람을 우선 태웠다. 심지어 영화내용에는 1등급의 사람들은 보트도 여유있게 탑승 한것처럼 표현을 하고 있더라. 그리고 나서 여자와 아이들을 먼저 태우려 하고, 결국 마지막에 죽는 사람들은 2,3등급 객실의 남자가 대부분 죽는것처럼 나온다. 캐글에서 받은 데이터도 실제로 이러한지 알아보면서 분석을 해보자.
패키지 불러오기&데이터 가져오기
library(tidyverse)
library(ggplot2)
library(plotly)
library(rpart)
library(rpart.plot)
library(caret)
library(e1071)
library(randomForest)
library(patchwork)
training_set <- read.csv("/home/owen/file/titanic/train.csv")
test_set <- read.csv("/home/owen/file/titanic/test.csv")탐색적 데이터 분석(EDA)
데이터 파악
각각의 데이터를 파악해보자. 영화에 표현되었던 객실(Pclass), 성별(Sex), 나이(Age)
str(training_set)## 'data.frame': 891 obs. of 12 variables:
## $ PassengerId: int 1 2 3 4 5 6 7 8 9 10 ...
## $ Survived : int 0 1 1 1 0 0 0 0 1 1 ...
## $ Pclass : int 3 1 3 1 3 3 1 3 3 2 ...
## $ Name : Factor w/ 891 levels "Abbing, Mr. Anthony",..: 109 191 358 277 16 559 520 629 417 581 ...
## $ Sex : Factor w/ 2 levels "female","male": 2 1 1 1 2 2 2 2 1 1 ...
## $ Age : num 22 38 26 35 35 NA 54 2 27 14 ...
## $ SibSp : int 1 1 0 1 0 0 0 3 0 1 ...
## $ Parch : int 0 0 0 0 0 0 0 1 2 0 ...
## $ Ticket : Factor w/ 681 levels "110152","110413",..: 524 597 670 50 473 276 86 396 345 133 ...
## $ Fare : num 7.25 71.28 7.92 53.1 8.05 ...
## $ Cabin : Factor w/ 148 levels "","A10","A14",..: 1 83 1 57 1 1 131 1 1 1 ...
## $ Embarked : Factor w/ 4 levels "","C","Q","S": 4 2 4 4 4 3 4 4 4 2 ...- PassengerID: 승객 고유번호
- Survived: 생존여부 0=No/ 1=Yes
- Pclass: 1등급, 2등급, 3등급
- int형으로 되어있기에 factor형으로 변경필요
- Name: 승객명
- factor형으로 되어있기에 character형으로 변경필요
- Sex: 성별
- Age: 나이
- SibSp: 함께 탑승한 배우자 또는 형제의 수
- Ticket: 티켓번호
- factor형으로 되어있기에 character형으로 변경필요
- Fare: 티켓요금
- Cabin: 선실번호
- factor형으로 되어있기에 character형으로 변경필요
- Embarked: 탑승한 곳 각각 “C”, “Q”, “S”는 탑승한 곳을 뜻하는 것으로 예상
# Train set cleansing
training_set$Pclass <- as.factor(training_set$Pclass)
training_set$Name <- as.character(training_set$Name)
training_set$Ticket <- as.character(training_set$Ticket)
training_set$Cabin <- as.character(training_set$Cabin)
# Test set cleansing
test_set$Pclass <- as.factor(test_set$Pclass)
test_set$Name <- as.character(test_set$Name)
test_set$Ticket <- as.character(test_set$Ticket)
test_set$Cabin <- as.character(test_set$Cabin)
test_set$Age[is.na(test_set$Age)] <- mean(test_set$Age, na.rm = T)데이터 Summary
Summary() 함수를 사용해서 데이터의 요약정보를 불러오자.
- Pclass는 각각 1등급: 216명, 2등급: 184명, 3등급: 491명
- 성별은 남자: 314명, 여자: 577명
- 나이는 최솟값이 0.42 세, 최댓값이 80세. 평균: 29.7세, NA(집계되지 않은 나이): 177명
summary(training_set)## PassengerId Survived Pclass Name Sex
## Min. : 1.0 Min. :0.0000 1:216 Length:891 female:314
## 1st Qu.:223.5 1st Qu.:0.0000 2:184 Class :character male :577
## Median :446.0 Median :0.0000 3:491 Mode :character
## Mean :446.0 Mean :0.3838
## 3rd Qu.:668.5 3rd Qu.:1.0000
## Max. :891.0 Max. :1.0000
##
## Age SibSp Parch Ticket
## Min. : 0.42 Min. :0.000 Min. :0.0000 Length:891
## 1st Qu.:20.12 1st Qu.:0.000 1st Qu.:0.0000 Class :character
## Median :28.00 Median :0.000 Median :0.0000 Mode :character
## Mean :29.70 Mean :0.523 Mean :0.3816
## 3rd Qu.:38.00 3rd Qu.:1.000 3rd Qu.:0.0000
## Max. :80.00 Max. :8.000 Max. :6.0000
## NA's :177
## Fare Cabin Embarked
## Min. : 0.00 Length:891 : 2
## 1st Qu.: 7.91 Class :character C:168
## Median : 14.45 Mode :character Q: 77
## Mean : 32.20 S:644
## 3rd Qu.: 31.00
## Max. :512.33
## 결측치 파악
결측치를 파악해보자. 결측치가 177개이며 컬럼별로 파악해보면 다음과 같다.
colSums(is.na(training_set))## PassengerId Survived Pclass Name Sex Age
## 0 0 0 0 0 177
## SibSp Parch Ticket Fare Cabin Embarked
## 0 0 0 0 0 0Age 결측치를 처리하는데 있어서 여러가지 방법이 있는데, 그 중 대표적인 것들이 NA제거, 평균값으로 대치, 행,열 제거가 있습니다. 이번에는 NA를 제거 하려고 하는데, 이유는 다음과 같다.
- 결측치의 갯수가 그리 많지 않다.
- 나이데이터를 평균을 냈다가 177개의 평균값이 생존에 영향을 끼칠수도 있을까 싶다.
training_set <- training_set %>%
drop_na()시각화
이번에는 데이터를 시각화해서 파악해보자. 여러 변수가 있지만 영화를 통해 파악해보기로 했기도 해서 성별, Pclass, 나이만 간단히 보자.
성별 -그래프를 보면 남자의 생존 비율이 여자보다 확실히 떨어지는것을 알 수 있다.
- 객실
- 객실에 따라서도 사망자수는 꽤 차이를 볼 수 있다.
- 나이
- 나이는 숫자형으로 되어 있어서 mutate(), case_when()함수를 사용해서 범주형 변수를 하나 만들었다. 10살 기준으로 끊어서 만들었으며, 특별한 이유는 없다. 그래프를 보면 10살 이하, 60살 이상은 적은 사망자수가 있는 반면, 20~50대에는 많은 사망자수가 있음을 볼 수 있다. 위에 게시한 타이타닉 영화 한장면만 봐도 어느정도는 알 수 있는 부분이다.
training_set <- training_set %>%
mutate(Ages = case_when(
Age < 10 ~ "Under 10",
Age < 20 ~ "10 ~ 20",
Age < 30 ~ "20 ~ 30",
Age < 40 ~ "30 ~ 40",
Age < 50 ~ "40 ~ 50",
Age < 60 ~ "50 ~ 60",
TRUE ~ "over 60"
))
training_set$Ages <-
factor(training_set$Ages,
levels = c("Under 10", "10 ~ 20", "20 ~ 30", "30 ~ 40", "40 ~ 50", "50 ~ 60", "over 60"))
plot_1 <- ggplot(training_set, aes(x=Survived, fill = Sex)) +
geom_bar() +
ggtitle("Survived by Sex") +
theme(legend.position="bottom")
plot_2 <- ggplot(training_set, aes(x = Survived, fill = Pclass)) +
geom_bar() +
ggtitle("Survived by Pclass") +
theme(legend.position="bottom")
plot_3 <- training_set %>%
ggplot(aes(x = Survived, fill = Ages)) +
geom_bar() +
ggtitle("Survived by Ages") +
theme(legend.position="bottom")
(plot_1 + plot_2) / plot_3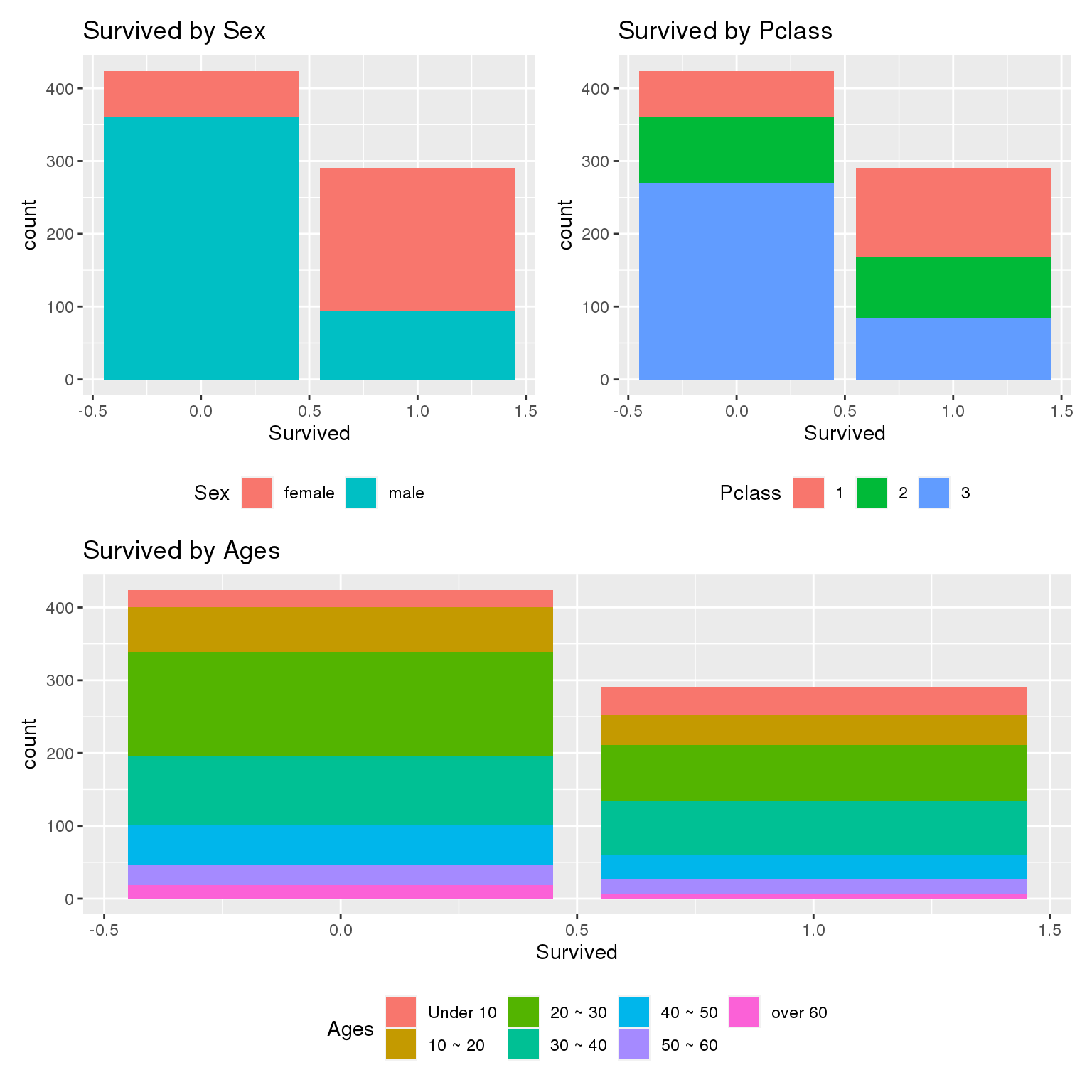
모델: Random Forest
데이터 파악, 전처리, 시각화까지 모두 진행 했으니 이제 생존 예측을 해보자. 모델은 Random Forest를 사용할 것이며 캐글에서 유명한, xgboost, lightbgm만큼은 아니더라도 빠른 속도와, 적당히 높은 성능을 보이고 있다. 종속변수는 Survived, 독립변수는 Sex와 Pclass, age로 사용하려 한다.
training_set$Survived <- as.factor(training_set$Survived)
# RandomForest 모델 생성
rf_m <- randomForest(Survived ~ Pclass + Age + Sex, data = training_set)
# importance
rf_info <- randomForest(Survived ~ Sex + Age + Pclass , data = training_set, importance = T)결과해석
결과를 보면 성별, 객실, 나이 순으로 데이터의 중요도를 나타낸것을 볼 수 있다. 영화에 의존해서 데이터를 파악하다보니 꽤나 맘에 드는 순서가 나온것 같다.
# 데이터의 중요도 확인
importance(rf_info)## 0 1 MeanDecreaseAccuracy MeanDecreaseGini
## Sex 42.44084 55.82354 51.51348 81.61038
## Age 18.00044 16.35680 23.21590 19.57022
## Pclass 23.51738 26.75256 27.51282 33.60847#데이터의 중요도 시각화
varImpPlot(rf_info)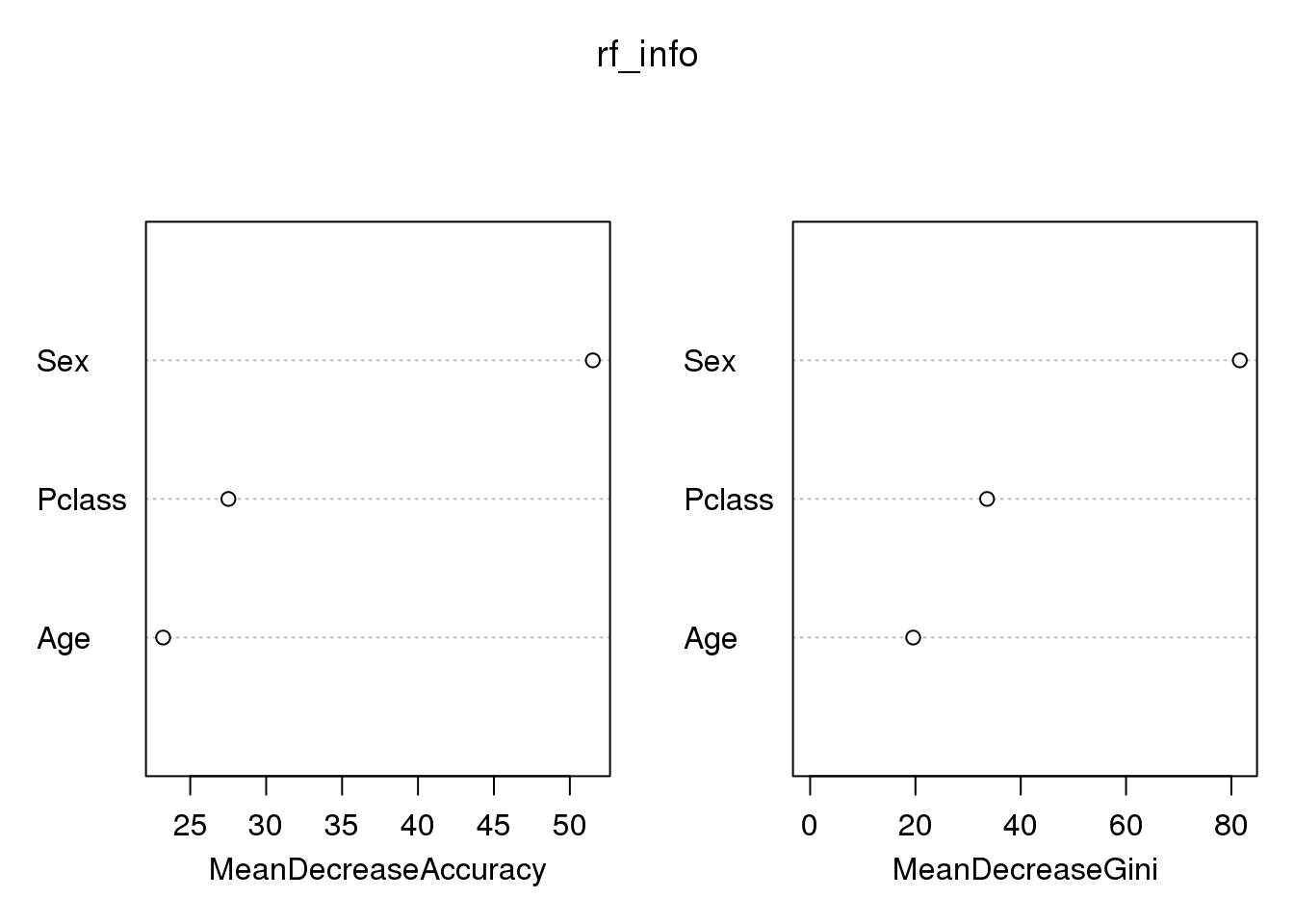
# test 결과 확인
rf_p <- predict(rf_m, newdata=test_set, type="class")제출 및 확인
랜덤포레스트로 분석해본 결과는 다음과 같다.
- Random Forest Score: 0.75598
solution <- data.frame(PassengerID = test_set$PassengerId, Survived = rf_p)
write.csv(solution, "solution.csv", row.names = FALSE)총평
캐글에서 타이타닉을 하려는데 문득 영화가 생각이 났었다. 그래서 영화의 내용을 기반으로 분석을 해보면 어떨까? 하는 생각으로 가볍게 분석을 시도해봤다. 상당히 간단하게 진행을 했지만 다른 타이타닉 분석글들을 보면 높은 수준의 글들이 있는걸 볼 수 있는데, 다음에는 이러한 것들을 많이 필사 해가면서 수준을 높혀야 겠다.