 Porto Seguro’s Safe Driver Prediction 링크: Porto Seguro’s Safe Driver Prediction
Porto Seguro’s Safe Driver Prediction 링크: Porto Seguro’s Safe Driver Prediction
About Automl h2o
AutoML h2o를 사용해 캐글의 Porto Seguro’s Safe Driver Prediction를 분석 해보자. 캐글을 병행하면서 R에서 Automl h2o를 사용할 수 있는 방법을 알게 되었고, 이를 어떻게 사용할 수 있을까 찾다가 선정한 주제였다. 당장은 Automl h2o사용에 있어서 부족한게 많아 상당히 많은 사이트를 참고 하고, 캐글 노트북을 참고하고 필사하게 되었다. 높은 난이도로 R with Automl h2o라는 주제의 블로그는 다음에 시간이 남을때 써보기로 하고 이번에는 Reference를 먼저 소개 하도록 하겠다.
Reference
다음은 H2o automl을 공부하는데 있어서 참고 할만한 링크와 Kaggle에서 Porto Seguro’s Safe Driver Prediction를 h2o automl을 사용해서 분석한 노트북의 출처이다.
- H2O AutoML
- xwMOOC님 블로그: 순수 H2O AutoML
- BBSSDDSD Rpubs: H2O 소개 및 간단한 사용법
- H2O 튜토리얼: h2o tutorials
- H2O AutoMA & Kaggle
- Troy Walters: h2o AutoML
- Bhavesh Ghodasara: AutoML(h2o) Trial
- Kaggle
- Heads or Tails: Steering Wheel of Fortune - Porto Seguro EDA
- Troy Walters: A Very Extensive Porto Exploratory Analysis
- 사자처럼 우아하게님 블로그: Porto Seguro’s Safe Driver Prediction 대회 소개 / 지니계수 란?
Porto Seguro’s Safe Driver Prediction
이제 본격적으로 Porto Seguro’s Safe Driver Prediction에 대해 알아보도록 하자. 데이터를 통해 운전자가 내년에 보험청구를 하는지 여부를 예측하는것이 목표다.
평가
이번 대회는 Normalized Gini Coefficient로 평가를 하게 된다. 먼저 Gini Coefficient를 이해 해보자면 다음과 같다.
지니 계수( - 係數, 영어: Gini coefficient, 이탈리아어: coefficiente di Gini)는 경제적 불평등(소득 불균형)을 계수화 한 것이다. 오늘날 가장 널리 사용되는, 불평등의 정도를 나타내는 통계학적 지수로, 이탈리아의 통계학자인 코라도 지니(Corrado Gini)가 1912년 발표한 논문 “Variabilità e mutabilità”에 처음 소개되었다. 서로 다른 로렌츠 곡선들이 교차하는 경우 비교하기가 곤란하다는 로렌츠 곡선의 단점을 보완할 수 있다. 지니 계수는 소득 분배의 불평등함 외에도, 부의 편중이나 에너지 소비에 있어서의 불평등함에도 응용된다.

출쳐: 위키백과 지니계수
데이터 파악
- 각각의 컬럼은 다음과 같이 태그 되어 있다.
- ind, reg, car, calc
- 컬럼 이름으로 데이터의 형식을 알 수 있는데 이는 다음과 같다.
- ’_bin’: Binary Features
- ’_cat’: Categorical Features
- 그외: Continuous 또는 Ordinal Features
- -1은 Null(결측치)를 의미한다.
사전 준비
패키지 불러오기 & 데이터 로드
library(readr)
library(tidyverse)
library(ggplot2)
library(dplyr)
library(pROC)
library(h2o)
library(caret)
library(corrplot)
library(ggthemes)
train_set <- read_csv("/home/owen/file/train.csv")
test_set <- read_csv("/home/owen/file/test.csv")H2O init
h2o.init() 함수를 통해 h2o와 R을 연결 시켜준다. 연결을 시켜주면 다음과 같은 정보를 얻을 수 있다. 자세한 내용은 다음을 참고 하자. - 참고: R과 h2o 연결하기
h2o.init()## Connection successful!
##
## R is connected to the H2O cluster:
## H2O cluster uptime: 45 minutes 17 seconds
## H2O cluster timezone: Asia/Seoul
## H2O data parsing timezone: UTC
## H2O cluster version: 3.30.0.1
## H2O cluster version age: 2 months and 19 days
## H2O cluster name: H2O_started_from_R_owen_qvv887
## H2O cluster total nodes: 1
## H2O cluster total memory: 1.52 GB
## H2O cluster total cores: 2
## H2O cluster allowed cores: 2
## H2O cluster healthy: TRUE
## H2O Connection ip: localhost
## H2O Connection port: 54321
## H2O Connection proxy: NA
## H2O Internal Security: FALSE
## H2O API Extensions: Amazon S3, XGBoost, Algos, AutoML, Core V3, TargetEncoder, Core V4
## R Version: R version 3.6.0 (2019-04-26)데이터 해석
데이터 구조
# str(train_set)데이터 요약정보
# summary(train_set)데이터 전처리
간단하게 전처리를 해보도록 하자. 앞서 말했듯이 -1로 되어 있는 데이터는 결측치 이므로 이는 NA로 변경 시켜 주자. 그리고 ’_cat’인 컬럼은 모두 factor형식으로 바꿔 주도록 해준다.
train_set[train_set == -1] <- NA
test_set[test_set == -1] <- NA
cat_vars <- names(train_set)[grepl('_cat$', names(train_set))]
train_set <- train_set %>%
mutate_at(.vars = cat_vars, .funs = as.factor)
test_set <- test_set %>%
mutate_at(.vars = cat_vars, .funs = as.factor)시각화
Target별 분포
Target별 분포를 파악해보자.
ggplot(data = train_set, aes(x = as.factor(target))) +
geom_bar(fill = "#D9230F") +
labs(title = 'Target별 분포',
x = "Target",
y = "Target 개수")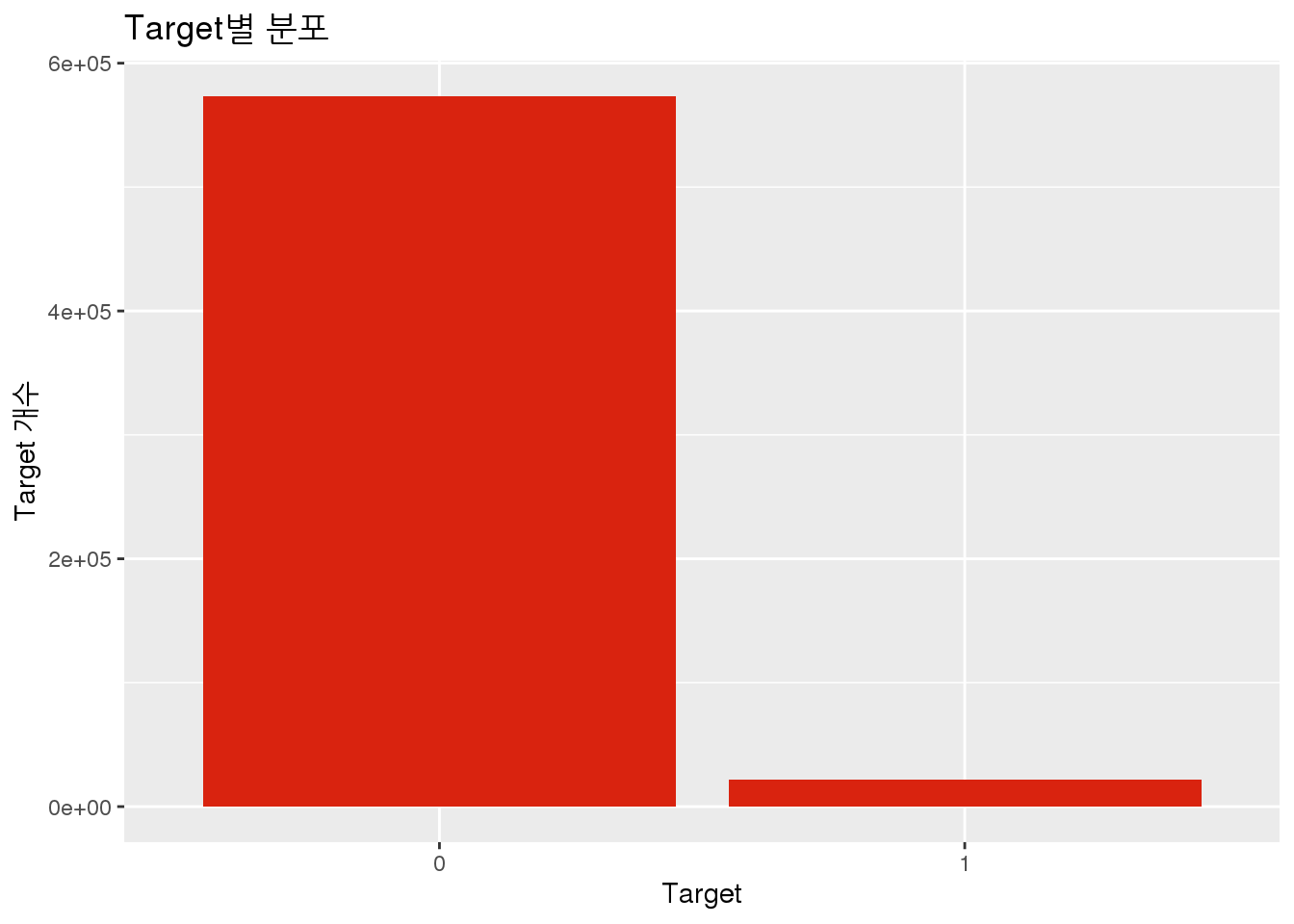
결측치 파악
결측치 시각화
결측치의 비율을 시각화 해서 파악을 해보자. 59개의 컬럼중 단 몇개의 데이터만이 상당히 많은 비율의 결측치를 갖고 있음을 알 수 있다.
data.frame(feature = names(train_set),
per_miss = map_dbl(train_set, function(x) { sum(is.na(x)) / length(x) })) %>%
ggplot(aes(x = reorder(feature, per_miss), y = per_miss)) +
geom_bar(stat = 'identity', color = 'white', fill = '#D9230F') +
theme(axis.text.x = element_text(angle = 90, hjust = 1)) +
coord_flip() +
labs(x = '', y = '결측치 비율 (%)', title = '컬럼별 결측치 비율') +
scale_y_continuous(labels = scales::percent)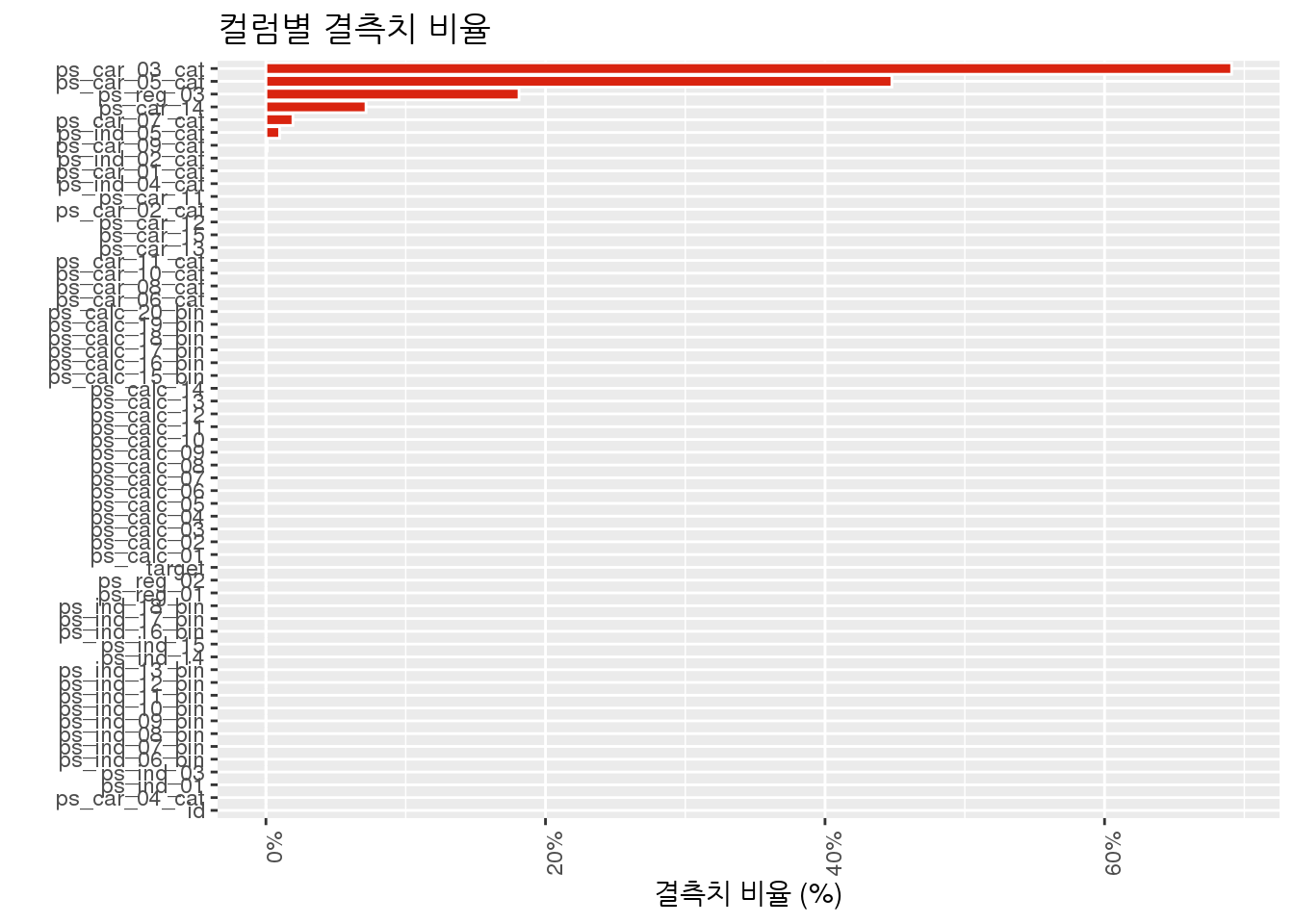
결측치 테이블
각 컬럼들의 결측치를 테이블로 좀 더 자세히 보도록 하자. 상위 10개만 뽑아서 확인해보면 다음과 같다.
missing_df <- data.frame(feature = names(train_set),
per_miss = round(map_dbl(train_set, function(x) { sum(is.na(x)) / length(x) }) * 100,2)) %>%
arrange(desc(per_miss)) %>%
head(10)
rownames(missing_df) <- NULL
missing_df## feature per_miss
## 1 ps_car_03_cat 69.09
## 2 ps_car_05_cat 44.78
## 3 ps_reg_03 18.11
## 4 ps_car_14 7.16
## 5 ps_car_07_cat 1.93
## 6 ps_ind_05_cat 0.98
## 7 ps_car_09_cat 0.10
## 8 ps_ind_02_cat 0.04
## 9 ps_car_01_cat 0.02
## 10 ps_ind_04_cat 0.01상관계수 파악
상관계수 시각화
각 데이터들간의 상관계수 plot을 그려 파악해보도록 하자. 데이터의 갯수가 상당히 많아서 테이블로 표시해도 큰 의미는 없으니 그래프를 통해 간단하게만 보도록 하자.
train_set %>%
select(-starts_with("ps_calc"), -ps_ind_10_bin, -ps_ind_11_bin, -ps_car_10_cat, -id) %>%
mutate_at(vars(ends_with("cat")), funs(as.integer)) %>%
mutate_at(vars(ends_with("bin")), funs(as.integer)) %>%
mutate(target = as.integer(target)) %>%
cor(use="complete.obs", method = "spearman") %>%
corrplot(type="lower", tl.col = "black", diag=FALSE)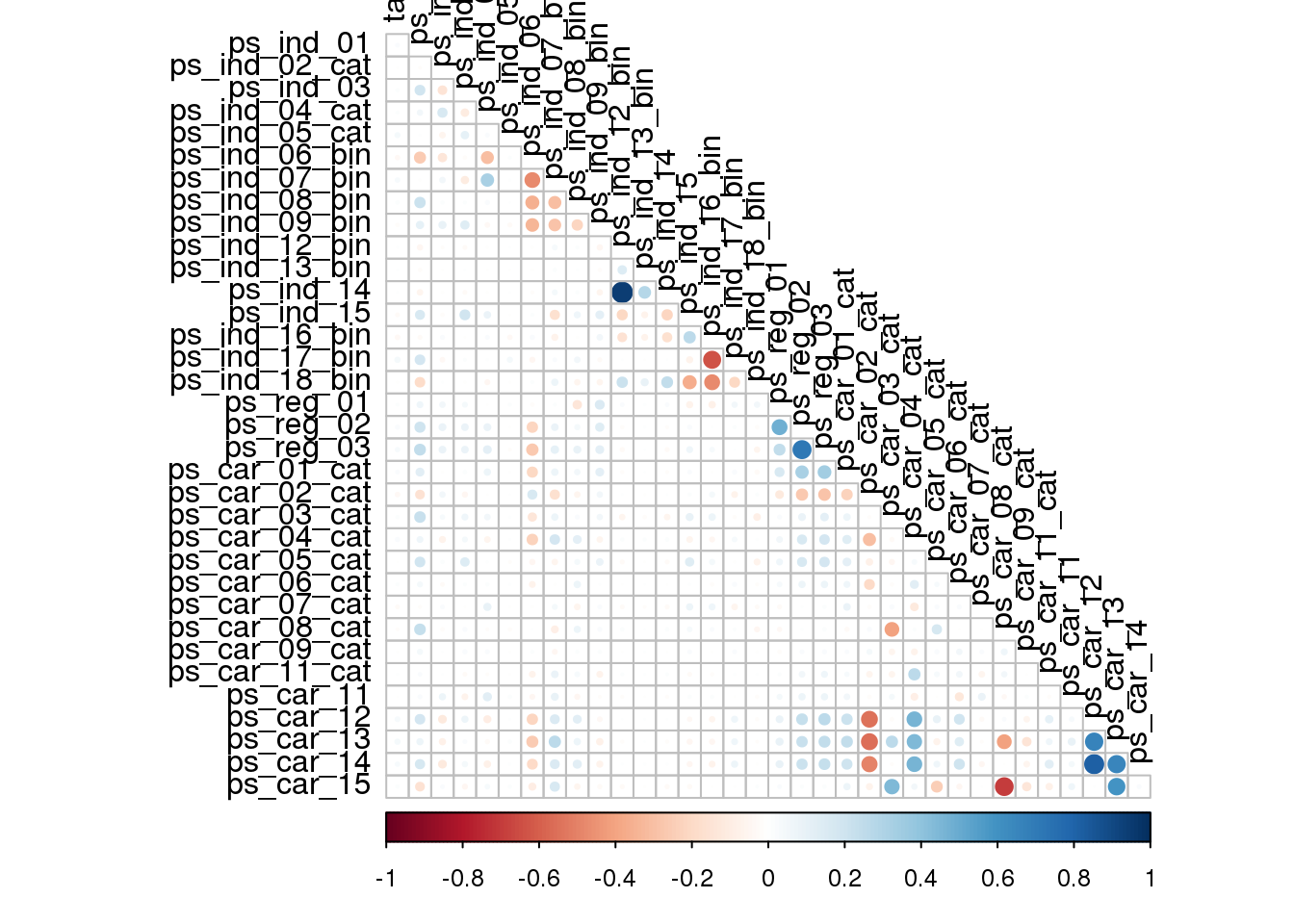
모델링
Train / Valid
시각화까지 진행 했으니 이제 모델을 돌려보자. 우선 Training데이터를 Train / valid 데이터로 분류를 해서 테스트를 진행 해보자. 이후에 Test데이터로 평가를 진행 해보려 한다.
진행 하는데 있어 h2o모델을 돌리기 위해서는 데이터를 as.h2o()함수를 통해 형식을 h2o에 맞게 해주어야 하나보다.
set.seed(32)
index <- sample(1:nrow(train_set), nrow(train_set) * 0.7)
tiny_train <- train_set[index, ]
train_val <- train_set[-index, ]
tiny_train.hex <- as.h2o(tiny_train)##
|
| | 0%
|
|======================================================================| 100%train_val.hex <- as.h2o(train_val)##
|
| | 0%
|
|======================================================================| 100%test.hex <- as.h2o(test_set)##
|
| | 0%
|
|======================================================================| 100%target <- "target"
predictors <- setdiff(names(tiny_train.hex), target)모델 생성
이제 이번 블로그의 핵심인 h2o.automl()함수를 사용해서 모델을 돌려보자. h2o.automl에 대해 자세한 사항은 다음을 참고 하자.
- 참고: h2o로 모델링 해보기
automl_h2o_models <- h2o.automl(
x = predictors,
y = target,
training_frame = tiny_train.hex,
leaderboard_frame = train_val.hex,
max_runtime_secs = 1000
)
automl_leader <- automl_h2o_models@leader
# Predict on test set
pred_conversion <- h2o.predict(object = automl_leader, newdata = test.hex)
pred_conversion <- as.data.frame(pred_conversion)
Submission <- cbind(test_set$id, pred_conversion)
colnames(Submission) <- c("id", "target")
write.csv(Submission, "Submission_AutoML.csv", row.names = F)Score

총평
h2o.automl을 알게 되어 R에서 적용해볼 기회가 생겼다.
상당히 많은 난관이 있었는데 첫번째로는 h2o를 R에 재설치 하는것. 패키지가 설치 되어 있어서 정말 놀랐는데 기억을 더듬어 보니, 꽤 오래전에 h2o패키지를 설치 해두었던 적이 있었다. 그래서 오랜만에 실행을 했더니 버전 문제로 warning이 나와서 다시 설치를 하는데 많은 시간을 쏟았다.
그리고 h2o.automl이 무엇인지 자료 조사 해보는 과정. automl은 어딘가에서 듣기만 했고, h2o는 패키지를 설치 했던 기억만 있지, 이번에 하면서 너무도 생소했었다. r에서 h2o가 어떻게, automl은 또 어떻게 진행되는지 알아보는 시간이 꽤 오래 걸렸다.
마지막 난관인데, 이 기술들을 가지고 어떻게 써먹을 수 있을까? 하는 문제였다. 어느순간부터 교과서형 공부 하는것을 별로 안좋아하게 되었는데, 100의 공부를 하고 10정도를 실전에 쓰는 느낌? 그래서 이번에도 실전에는 어떻게 활용할 수 있을까 하다가 생각이 났던 것이 캐글. 캐글에서도 많은 자료가 없었고, 적당한 주제와 당장 내가 h2o.automl()로 할 수 있어 보이는 분류 데이터를 찾느라 시간이 많이 걸렸다.
정말 새로운 ’그 무언가’를 해봤다. 어디서 듣기만 했다가 시작한것이 아니라 아예 처음부터 생소한 것들을 공부해가면서 이번 캐글 준비를 해봤는데, 이제 이런것을이 하나둘씩 쌓여가겠지.