
이번에는 AWS에서 서비스 하는 RDS에 대해 작성을 해보려 한다. Amazon Relational Database Service(Amazon RDS)라고 사용하며 AWS 클라우드에서 관계형 데이터베이스를 더 쉽게 설치, 운영 및 확장할 수 있는 웹 서비스라고 한다. 현재 MySQL, Oracle, SQL Server, PostgreSQL, MariaDB, Aurora(MySQL과 호환)을 비롯한 총 6가지 데이터베이스 엔진을 지원하고 있으며, 이번에는 PostgreSQL을 구축해보고, R/Python에 연동을 하면서 마무리를 지어보려고 한다. RDS의 여러 기능과 이점을 설명하기 보다는 아주 간단하게 구축,연동에 초점을 맞추는것이 이번 블로그의 핵심이다. RDS에 대한 자세한 설명은 다음을 참고 하자.
RDS 생성
우선 몇단계를 걸쳐서 RDS를 생성 해보자.
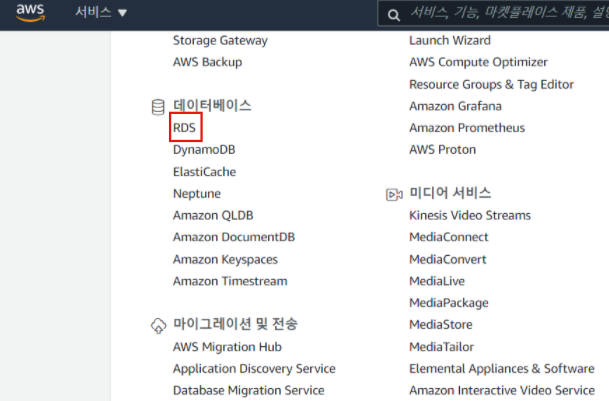
Step 1. 서비스 - 데이터베이스 - RDS
다음과 같이 RDS를 클릭하여 RDS의 기본 화면으로 넘어가자.
Step 2. Dashboard - 데이터베이스 생성 버튼
데이터베이스 생성 버튼 클릭

Step 3. 데이터베이스 생성방식/엔진옵션 설정
이제부터 DB를 만드는데 있어서 몇가지 옵션을 지정해주려고 한다. 우선 표준생성/손쉬운생성 두가지가 있는데 표준생성을 클릭해준다. 그리고 엔진 옵션에는 총 6가지의 데이터베이스가 있는데 이중에서는 PostgreSQL을 클릭해준다.

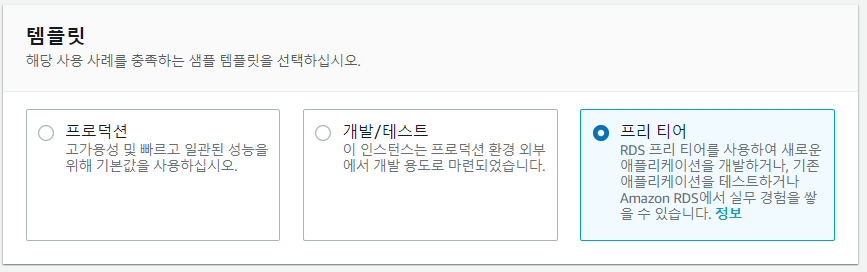
Step 4. 템플릿 설정
이제 템플릿을 선택 해야 하는데, 이중에서는 프리 티어를 설정 해주자.프로덕션이나 개발/테스트 옵션을 할경우 좀 더 높은 성능의 DB서버를 구축할 수 있으나, 요금이 꽤 나갈수 있으므로 상황에 따라서 잘 알아보고 선택 해주는 것이 좋다. 최근에 DB테스트를 하는데, 속도가 너무 나오지 않아서 좀 더 높은 성능을 알아보는 도중에 가격 때문에 일단은 다른 방향을 알아본 경험이 있기에 DBA분과 상의 하여 적정 데이터에 적정 서비스를 고려하여 선택 해주는것이 좋다. RDS요금은 다음을 참고하자.
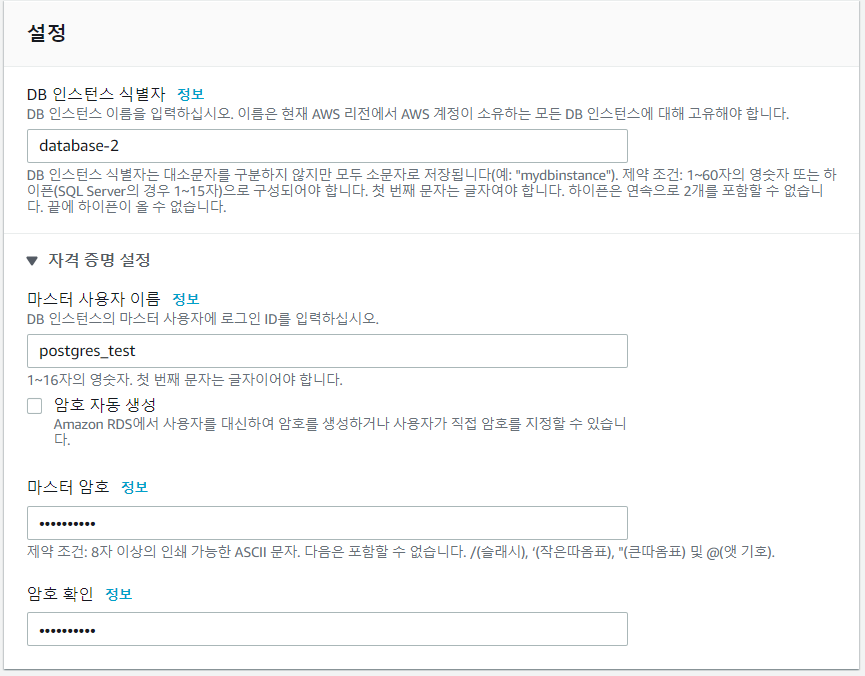
Step 5. DB 정보 입력
이제 DB정보를 입력하자. 여기서 좀 더 신경 써야 하는건 자격 증명 설정인데 마스터 사용자 이름과 마스터 암호는 R/Python연결시 꼭 필요하다. 여기서 사용한 정보는 다음과 같다.
- 마스터 사용자 이름: postgres_test
- 마스터 암호: mypassword
Step 6. DB 인스턴스 크기 설정
이제는 DB인스턴스 크기를 설정 해주자. 이 전에도 서술 했듯이, 각각의 성능과 그에 따른 요금이 있으며 db.t2.micro버전을 사용한다.

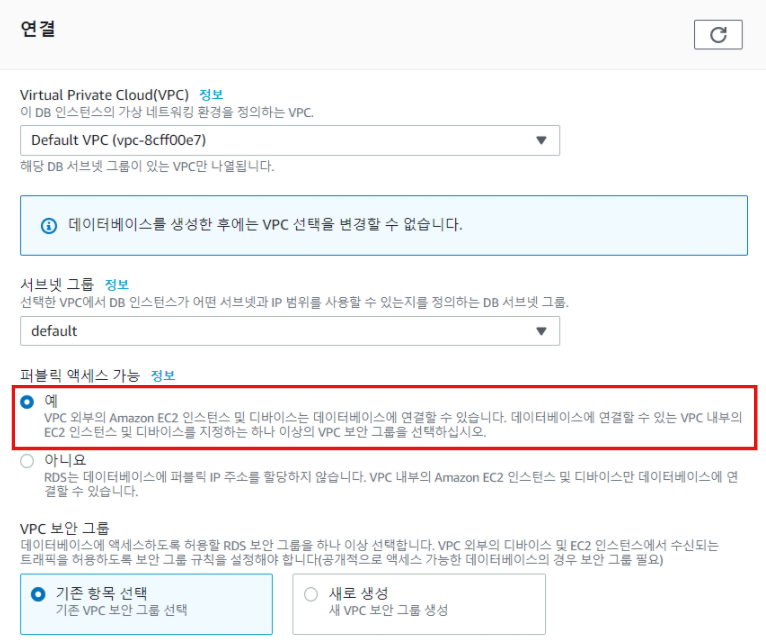
Step 7. 퍼블릭 액세스 설정
퍼블릭 액세스 설정 부분이다. 이번에는 개인 데탑에 R/Python연결 하려고 하기 때문에 퍼블릭 액세스에 예를 해주었다. 사실 이는 어느정도 보안 문제로 충분히 위험할 수 있으며, 이를 아니요로 했을경우에는 EC2에만 연결이 되게 된다. 현업에서 사용하게 된다면 특히 전문가와 상의를 하고 설정하는걸 추천.
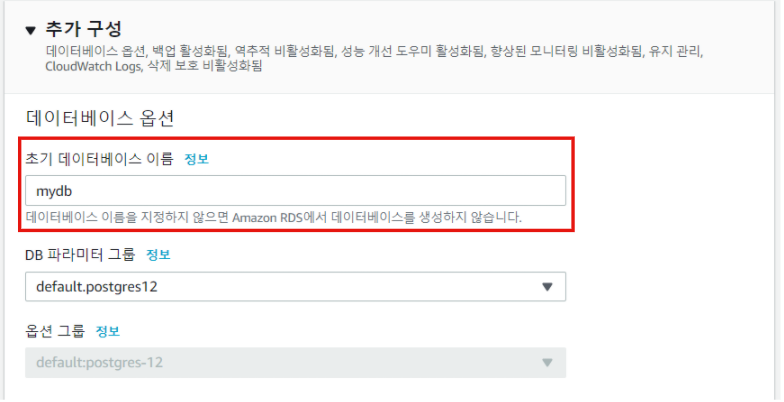
Step 8. 데이터베이스 이름 설정
이제는 데이터베이스의 이름을 설정해주자. 이 역시 R/Python 연결시 필요한 정보이다. 여기서 데이터베이스 정보는 다음과 같이 적어놓았다.
- 데이터베이스 이름: mydb
Step 9. 월별 추정 요금 확인/데이터베이스 생성
마지막으로 월별 추정 요금 확인란에서 월에 얼마의 비용이 나가는지 확인해보고 데이터베이스를 생성 해주자. 프리티어로 해서 무료로 나온다만 실제로는 월별 추정요금이 나오게 된다.

Step 10. RDS 생성중
성공적으로 생성된 모습. 생성 했을 경우 생각보다 시간이 꽤 걸리며 이는 약 5분정도.
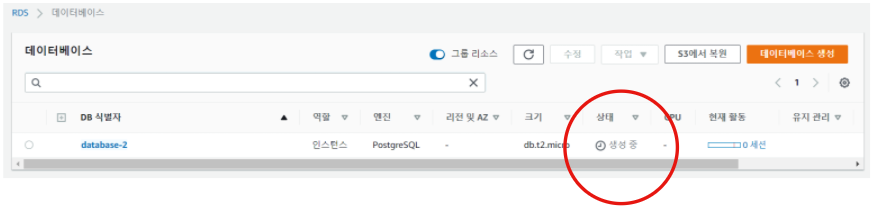
Step 11. 생성된 데이터베이스 정보 확인 (연결 & 보안 Tab)
RDS가 잘 생성이 되면 해당 DB를 클릭하여 다음의 정보를 확인해보자. 우선 연결 & 보안 부분에서 엔드포인트 와 포트 정보를 알아두어야 한다. 이 역시 R/Python에 연결할때 사용해야 하기 때문.
Step 12. 생성된 데이터베이스 정보 확인 (구성 Tab)
다음은 구성 탭을 확인해보자. 이곳에서는 생성한 DB의 간략한 정보를 확인할 수 있다. 이렇게 AWS에 RDS생성은 마무리가 되었다. 이제 R/Python에 연결하는 방법을 알아보자.

번외 - RDS 사용 중지
RDS 사용을 중지하기 위해서는 작업 필터에서 중지를 해주면 된다. EC2와 다르게 우클릭으로 작업 실행/중지가 아님.
RDS - R/Python 연결
생성한 RDS에 R/Python을 연결 하려고 한다. 처음에 R/Python을 접하다 보면 기본 데이터인 iris로 시작을 해서 점점 csv로 분석을 공부하게 되고 어느 순간부터 실제 DB에 연결해서 대용량의 데이터를 처리하게 되는데 이때, 사용하게 될 기능이다.
RDS - R 연결
이제 이렇게 생성한 RDS에 R을 연결 시켜 보자. 이때 사용할 library는 DBI, RpostgreSQL이다. 이때 중요한 점은, 이 전에 중요하게 알아두어야 했던 각각의 정보들이 필요하다.
- dbname: 초기에 설정한 database 이름
- host: RDS의 엔드포인트
- port: 포트 번호. PostgreSQL의 포트번호는 5432
- user: 마스터 사용자의 이름
- password: 마스터 암호
library(DBI)
library(RPostgreSQL)
library(dplyr)
drv <- dbDriver("PostgreSQL")
con <- dbConnect(drv,
dbname = "mydb",
host = "database-2.chye2xy6xz7a.ap-northeast-2.rds.amazonaws.com",
port = 5432,
user = "postgres_test",
password = "mypassword")이렇게 RDS의 DB정보를 con에 저장해주고 테스트를 해보자. dbWriteTable()를 사용하여 iris를 rds_test_iris라고 저장한다. R에서 DB를 사용하는 간략한 방법은 과거에 포스팅한적이 있는데, 다음을 참고 하자.
dbWriteTable(con, "rds_test_iris", iris)## [1] FALSErds_test_iris라는 테이블에 iris가 잘 들어 왔는지 확이하기 위해 다음의 함수를 작성 한다. 이때 사용한 tbl()함수는 dplyr패키지의 함수로, 대용량의 데이터를 쿼리로 불러올때, 메모리의 절약을 도와줄 수 있다. 작성 결과 iris데이터가 잘 나오는것으로 봐서 RDS와 R이 잘 연동 된것을 확인할 수 있었다.
tbl(con, "rds_test_iris")## # Source: table<rds_test_iris> [?? x 6]
## # Database: postgres 12.0.5
## # [@database-2.chye2xy6xz7a.ap-northeast-2.rds.amazonaws.com:5432/mydb]
## row.names Sepal.Length Sepal.Width Petal.Length Petal.Width Species
## <chr> <dbl> <dbl> <dbl> <dbl> <chr>
## 1 1 5.1 3.5 1.4 0.2 setosa
## 2 2 4.9 3 1.4 0.2 setosa
## 3 3 4.7 3.2 1.3 0.2 setosa
## 4 4 4.6 3.1 1.5 0.2 setosa
## 5 5 5 3.6 1.4 0.2 setosa
## 6 6 5.4 3.9 1.7 0.4 setosa
## 7 7 4.6 3.4 1.4 0.3 setosa
## 8 8 5 3.4 1.5 0.2 setosa
## 9 9 4.4 2.9 1.4 0.2 setosa
## 10 10 4.9 3.1 1.5 0.1 setosa
## # … with more rowsPython 연결
이번에는 RDS와 Python의 연동을 확인해보자. psycopg2를 사용하고 이에 대한 자세한 정보는 다음의 출처를 따른다.
import sys
import os
import pandas as pd
import base64
import requests
import psycopg2 as pg2이곳에도 역시 각각의 정보는 다음을 따른다.
- database: 초기에 설정한 database 이름
- host: RDS의 엔드포인트
- port: 포트 번호. PostgreSQL의 포트번호는 5432
- user: 마스터 사용자의 이름
- password: 마스터 암호
conn=pg2.connect(database="mydb",
host="database-2.chye2xy6xz7a.ap-northeast-2.rds.amazonaws.com",
port="5432",
user="postgres_test",
password="mypassword")이렇게 pg2.connct()를 사용해 conn을 만들었으면 cursor를 통해 sql문을 주고 받는다. 이후 이 커서 객체인 cur의 execute()명령을 실행하여 SQL쿼리를 실행한다.
cur=conn.cursor()
cur.execute("SELECT * FROM rds_test_iris;")실행된 쿼리는 pd.DataFrame를 사용하여 표현해주면 rds_test_iris라고 만들어둔 iris데이터가 다음과 같이 표현되는 것을 확인할 수 있다.
pd.DataFrame(cur.fetchall())## 0 1 2 3 4 5
## 0 1 5.1 3.5 1.4 0.2 setosa
## 1 2 4.9 3.0 1.4 0.2 setosa
## 2 3 4.7 3.2 1.3 0.2 setosa
## 3 4 4.6 3.1 1.5 0.2 setosa
## 4 5 5.0 3.6 1.4 0.2 setosa
## .. ... ... ... ... ... ...
## 145 146 6.7 3.0 5.2 2.3 virginica
## 146 147 6.3 2.5 5.0 1.9 virginica
## 147 148 6.5 3.0 5.2 2.0 virginica
## 148 149 6.2 3.4 5.4 2.3 virginica
## 149 150 5.9 3.0 5.1 1.8 virginica
##
## [150 rows x 6 columns]총평
최근에 DB속도가 너무 느려, DB에 대해 좀 알아보게 되었다. 그러다 겸사겸사 AWS의 RDS랑 같이 사용해보려고 이러한 시도를 해봤으며, 여러가지 공부해야할 것들이 많은것을 알게 되었다. 데이터를 다루면서 DB는 그저 쿼리문만 작성을 하는 수준이었는데 이를 계기로 조금씩 알아보면, 이제 언젠가는 혼자서 인프라를 구축하게 되는 날이 오리라고 믿으며 마무리를 짓자.