k-최근접 이웃 회귀에 대해 알아보자. 이에 대한 내용은 혼자 공부하는 머신러닝+딥러닝의 Chapter 3-1를 기반으로 하며 이곳에 사용한 데이터를 사용할 예정이다. 여기서 사용하는 데이터는 농어 데이터를 사용하는데 기본적인 배경을 먼저 보자.
여름 농어 철로 농어 주문이 크게 늘어나자 한빛 마켓은 업계 최초로 농어를 무게 단위로 판매하려 합니다. 농어를 마리당 가격으로 판매했을 때 기대보다 볼품없는 농어를 받은 고객이 항의하는 일이발생했기 때문입니다. 무게 단위로 가격을 책정하면 고객들도 합리적이라고 생각하겠죠? 그런데 공급처에서 생선 무게를 잘못 측정해서 보냈습니다. 큰일이네요.
농어의 길이, 높이, 두께를 측정한 데이터가 주어져 있다. 또한 샘플로 56개의 무게를 측정한 데이터도 있으니 농어의 무게를 측정하기에 좋은 데이터로 보인다. 그러나 길이, 높이, 두께중 길이 만 사용해서 진행 한다. K-최근접 이웃 회귀를 하기전에 우선 K-최근접 이웃 분류와 회귀 알고리즘을 간단히 알아보자.
k-최근접 이웃 분류 알고리즘
k-최근접 이웃 분류 알고리즘은 다음과 같다. 예측하려는 샘플에 가장 가까운 샘플 k개를 선택. 그다음 이 샘플들의 클래스를 확인하여 다수 클래스를 새로운 샘플의 클래스로 예측한다. 다음 그림의 왼족에 k-최근접 이웃 분류가 잘 나타나 있다. k=3 (샘플이 3개)이라 가정하면 사각형이 2개로 다수이기 때문에 새로운 샘풀 X의 클래스는 사각형이 된다.

k-최근접 이웃 회귀 알고리즘
k-최근접 이웃 회귀는 다음과 같다. 우선 분류와 똑같이 예측하려는 샘플에 가장 가까운 샘플 k개를 선택. 하지만 회귀이기 때문에 이웃한 샘플의 타깃은 어떤 클래스가 아니라 임의의 수치이다. 이웃 샘플의 수치를 사용해 새로운 샘플 X의 타깃을 예측하는 방법은 이 수치들의 평균을 구하면 된다.

라이브러리
이제 다음을 통해 하나씩 확인해보자. 우선 이번에 필요한 라이브러리를 먼저 확인해보자. 각각 라이브러리의 사용 목적은 다음과 같다.
- numpy
- 사이킷런에서 사용할 훈련 세트(2차원 배열) 사용
- matplotlib.pyplot
- 산점도 시각화 사용
- sklearn.model_selection
- 사이킷런의 train_test_split()함수를 통해 Train/test set 나눔
- sklearn.neighbors
- k-최근접 이웃 회귀 알고리즘의 KNeighborsRegressor() 모델 사용
- sklearn.metrics
- mean_absolute_error() 함수를 사용하여 mae를구함
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsRegressor
from sklearn.metrics import mean_absolute_error 데이터 준비
이제 농어의 데이터를 준비 하자 데이터는 다음과 같다. 각각 길이와, 무게로 주어져 있다.
perch_length = np.array([8.4, 13.7, 15.0, 16.2, 17.4, 18.0, 18.7, 19.0, 19.6, 20.0, 21.0,
21.0, 21.0, 21.3, 22.0, 22.0, 22.0, 22.0, 22.0, 22.5, 22.5, 22.7,
23.0, 23.5, 24.0, 24.0, 24.6, 25.0, 25.6, 26.5, 27.3, 27.5, 27.5,
27.5, 28.0, 28.7, 30.0, 32.8, 34.5, 35.0, 36.5, 36.0, 37.0, 37.0,
39.0, 39.0, 39.0, 40.0, 40.0, 40.0, 40.0, 42.0, 43.0, 43.0, 43.5,
44.0])
perch_weight = np.array([5.9, 32.0, 40.0, 51.5, 70.0, 100.0, 78.0, 80.0, 85.0, 85.0, 110.0,
115.0, 125.0, 130.0, 120.0, 120.0, 130.0, 135.0, 110.0, 130.0,
150.0, 145.0, 150.0, 170.0, 225.0, 145.0, 188.0, 180.0, 197.0,
218.0, 300.0, 260.0, 265.0, 250.0, 250.0, 300.0, 320.0, 514.0,
556.0, 840.0, 685.0, 700.0, 700.0, 690.0, 900.0, 650.0, 820.0,
850.0, 900.0, 1015.0, 820.0, 1100.0, 1000.0, 1100.0, 1000.0,
1000.0])산점도
이제 이렇게 주어진 데이터가 어떤 형태를 나타내는진 산점도로 그려보자. matplotlib.plot의 sactter()함수를 사용한다. 산점도를 통해 확인할 수 있듯, 길이가 커짐에 따라 무게가 늘어나는 것을 확인할 수 있다.
plt.scatter(perch_length, perch_weight)
plt.xlabel('length')
plt.ylabel('weight')
plt.show()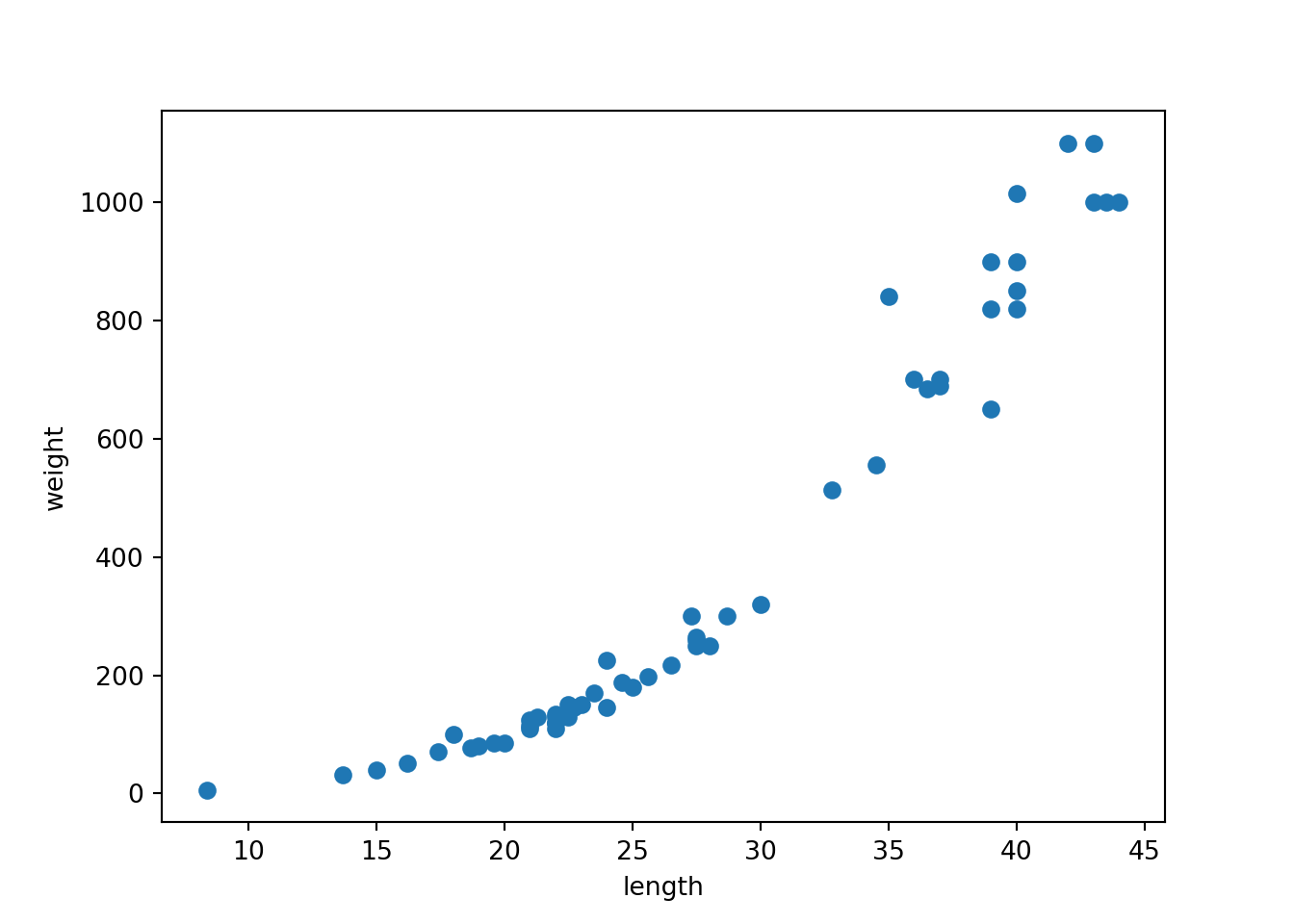
Train/test set
이제 머신러닝 모델에 사용하기위해 Train/test set으로 나누어 보자. sklearn.model_selection의 train_test_split() 함수를 사용한다.
train_input, test_input, train_target, test_target = train_test_split(
perch_length, perch_weight, random_state=42)이제 이 데이터를 2차원 배열로 변환 시켜주자. 사이킷런에 사용할 데이터는 2차원 배열이어야 한다. 이때 reshape() 메서드를 사용하는데, reshape(-1,1)를 사용하는 이유는, 배열의 크기를 자동으로 지정해주기 위함이다. 크기에 -1로 지정했을 경우 나머지 원소를 모두 채우라는 뜻이고, 두번째의 크기를 1로 하겠다는 의미이다. 이렇게 각각 (42,1), (14,1)의 2차원 배열을 만들어 두었다.
train_input = train_input.reshape(-1,1)
test_input = test_input.reshape(-1,1)
print(train_input.shape, test_input.shape)## (42, 1) (14, 1)모델 훈련
이제 사이킷런의 k-최근접 이웃 회귀 알고리즘을 구현한 KNeighborsRegressor()를 사용하다. 먼저 fit() 메서드로 훈련을 진행한다. 이때 k의 값은 5로 먼저 지정해주었다. 물론, 사이킷런의 k-최근접 이웃 알고리즘의 기본 k값은 5이다.
knr = KNeighborsRegressor()
knr.n_neighbors = 5
knr.fit(train_input, train_target)## KNeighborsRegressor()이제 score()메서드를 통해 점수를 확인 해보자. 회귀에서 score의 경우에는 결정계수로 평가를 내린다. \(R^2\)라고도 부르며 식은 다음과 같다.
print(knr.score(test_input, test_target))## 0.992809406101064이번에는 다른 평가를 해보자. 타깃과 예측한 값 사이의 차이를 구하면서 어느정도 예측을 벗어나는지 확인할 수 있는 방법이 있다. sklearn.metrics의 mean_absolute_error()함수를 사용하여 mae를 구해낸다. 다음을 확인하면 결과에서 예측이 평균적으로 19g정도 차이가 난다는 것을 확인할 수 있다. 이렇게 k-최근접 이웃 회귀는 간략하게 마무리를 짓는다. 과대,과소적합에 대한 내용이 따로 더 있었지만, 데이터의 양이 매우 부족하기 때문에 후에, 이를 응용하는 과정에서 이 부분에 대해 다룰수 있으면 다루려 한다.
test_prediction = knr.predict(test_input)
mae = mean_absolute_error(test_target, test_prediction)
print(mae)## 19.157142857142862총평
이번에 혼자 공부하는 머신러닝+딥러닝 이라는 책을 주제로 스터디를 진행 한다. 그동안 R로 모델을 돌리다가 이참에 파이썬으로 모델을 돌리는데, 스터디도 하면서 블로그에 기록을 남기기엔 아주 좋은 경험이 될것 같다.