지난번에 pykrx를 사용한 금융 데이터 분석 PART 1을 진행 했었다. 이번에는 PART 2를 진행 해보려고 한다. 지난번에는 주식 종목을 중심으로 데이터를 수집했었고, 이번에는 인덱스 정보를 위주로 진행을 해보려고 한다. 그전에 주식에서 사용하는 인덱스에 대해서 잠깐 알아보자.
인덱스란?
주가지수 인덱스는 주식 시장에서 특정 기업이나 기업들의 주식 가격의 상승과 하락을 측정하는 지표입니다. 이 지표는 일정한 규칙에 따라 계산되며, 일반적으로 특정 기준일을 기준으로 기업들의 시가총액, 주식 가격, 거래량 등의 정보를 이용하여 계산됩니다.
라고 한다. 여기서 조금 더 쉽게 설명하자면 일정한 규칙에 따라서 모아 놓은 정보라고 생각하면 된다. 코스피 200 이 이에 해당한다.
파이썬을 사용한 데이터 수집 가이드
라이브러리 호출
import pandas as pd
from pykrx import stock
from pykrx import bond
from time import sleep
from datetime import datetime
import os
import time날짜 호출
현재 날짜를 호출하자. 시작 날짜는 start_date로 20180101로 지정해주어 2018년 부터 수집을 해주도록 한다.
now = datetime.now()
today_date1 = now.strftime('%Y%m%d')
start_date = '20180101'Pykrx 를 사용한 데이터 수집
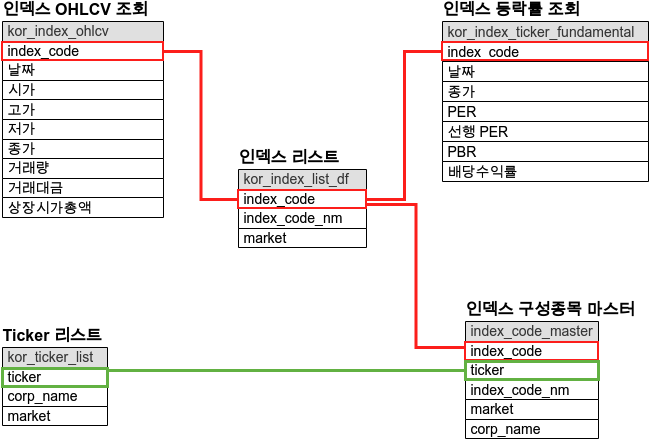
인덱스 리스트 생성
우선 인덱스 리스트를 생성해주자.
kor_index_list_df = pd.DataFrame()
market_list = ['KOSPI', 'KOSDAQ']
for market_nm in market_list:
kor_index_list = stock.get_index_code_list(market=market_nm)
for index_codes in kor_index_list:
index_name = stock.get_index_code_name(index_codes)
df = pd.DataFrame({'index_code':index_codes,
'index_code_nm':index_name,
'market': market_nm
}, index = [0])
kor_index_list_df = pd.concat([kor_index_list_df,df])
kor_index_list_df = kor_index_list_df.reset_index(drop = True)
kor_index_list_df.head()이렇게 index_code와 market과 함께 인덱스정보가 생성 되었다.
| index_code | index_code_nm | market |
|---|---|---|
| 1001 | 코스피 | KOSPI |
| 1002 | 코스피 대형주 | KOSPI |
| 1003 | 코스피 중형주 | KOSPI |
| 1004 | 코스피 소형주 | KOSPI |
| 1005 | 음식료품 | KOSPI |
이는 다음과 같이 저장해주고 인덱스 코드는 따로 만들어 주자.
kor_index_code_list = kor_index_list_df['index_code']
kor_index_list_df.to_csv(f'data_crawler/kor_index_list_df.csv', index=False, mode='w')인덱스 OHLCV 조회
이번에는 인덱스의 OHLCV 정보이다. stock.get_index_ohlcv()를 사용하며 지난 블로그와 형식은 같다.
for index_code in kor_index_code_list:
file_name = 'kor_index_ohlcv'
try:
df_raw = stock.get_index_ohlcv(start_date, today_date1, index_code)
df_raw = df_raw.reset_index()
df_raw['index_code'] = index_code
if not os.path.exists(f'data_crawler/{file_name}.csv'):
df_raw.to_csv(f'data_crawler/{file_name}.csv', index=False, mode='w')
else:
df_raw.to_csv(f'data_crawler/{file_name}.csv', index=False, mode='a', header=False)
print(f'{index_code} success')
except:
print(f'{index_code} fail') 간단하게 확인해보면 다음과 같은 테이블이 생성 된다.
df_raw.head(3).T| 0 | 1 | 2 | |
|---|---|---|---|
| 날짜 | 2023-06-01 00:00:00 | 2023-06-02 00:00:00 | 2023-06-05 00:00:00 |
| 시가 | 2574.46 | 2588.92 | 2621.76 |
| 고가 | 2582.46 | 2604.71 | 2621.76 |
| 저가 | 2566.04 | 2586.47 | 2608.74 |
| 종가 | 2570.3 | 2604.71 | 2616.49 |
| 거래량 | 76234358 | 73355328 | 83302457 |
| 거래대금 | 5240317905443 | 5477095023315 | 5074544647627 |
| 상장시가총액 | 1633027742856730 | 1654886981280910 | 1662376324326780 |
| index_code | 1002 | 1002 | 1002 |
인덱스 등락률 조회
이번에는 인덱스의 등락률 정보이다. stock.get_index_fundamental()를 사용하며 지난 블로그와 형식은 같다.
for index_code in kor_index_code_list:
file_name = 'kor_index_code_fundamental'
try:
df_raw = stock.get_index_fundamental(start_date, today_date1, index_code)
df_raw = df_raw.reset_index()
df_raw['ticker'] = index_code
if not os.path.exists(f'data_crawler/{file_name}.csv'):
df_raw.to_csv(f'data_crawler/{file_name}.csv', index=False, mode='w')
else:
df_raw.to_csv(f'data_crawler/{file_name}.csv', index=False, mode='a', header=False)
print(f'{index_code} success')
except:
print(f'{index_code} fail') 간단하게 확인해보면 다음과 같은 테이블이 생성 된다.
df_raw.head(3).T| 0 | 1 | 2 | |
|---|---|---|---|
| 날짜 | 2023-06-01 00:00:00 | 2023-06-02 00:00:00 | 2023-06-05 00:00:00 |
| 종가 | 2570.3 | 2604.71 | 2616.49 |
| 등락률 | -0.4 | 1.34 | 0.45 |
| PER | 13.92 | 14.11 | 14.17 |
| 선행PER | 0.0 | 0.0 | 0.0 |
| PBR | 1.06 | 1.07 | 1.08 |
| 배당수익률 | 1.9 | 1.88 | 1.87 |
| index_code | 1002 | 1002 | 1002 |
인덱스 구성 종목 확인
이번에는 인덱스의 구성 종목을 확인해보자. 처음에 설명했듯, 인덱스는 특정한 규칙을 기준으로 주식정보를 모아놓은 것이라고 설명을 했었고 그 예로 코스피 200을 예로 들었다. 우리가 수집했던 인덱스에는 어떤 주식 정보들이 모아져 있는지 확인해보자. stock.get_index_portfolio_deposit_file()함수를 사용한다. 그리고 이는 저장하지 않는다. 2번의 merge를 통해 인덱스 마스터를 따로 만들어 주도록 하자.
index_code_info = pd.DataFrame()
for i in kor_index_list_df['index_code']:
pdf = stock.get_index_portfolio_deposit_file(str(i))
df = pd.DataFrame({'ticker':pdf,
'index_code': str(i)})
index_code_info = pd.concat([index_code_info, df])
index_code_info = index_code_info.reset_index(drop = True)이렇게 수집을 했고 확인해보면 다음과 같이 index_code에 따른 ticker를 확인할 수 있다. 그러나 여기서 우리는 index_code의 정보를 알고 싶으니 이에 따른 merge 과정이 한번 필요 하다.
index_code_info.head()| ticker | index_code |
|---|---|
| 005930 | 1001 |
| 373220 | 1001 |
| 000660 | 1001 |
| 207940 | 1001 |
| 006400 | 1001 |
우선 다음을 보자. 처음에 수집했던 index 정보 이고 우리는 여기서 index_code를 기준으로 merge를 진행 해주도록 하겠다.
kor_index_list_df.head()| index_code | index_code_nm | market |
|---|---|---|
| 1001 | 코스피 | KOSPI |
| 1002 | 코스피 대형주 | KOSPI |
| 1003 | 코스피 중형주 | KOSPI |
| 1004 | 코스피 소형주 | KOSPI |
| 1005 | 음식료품 | KOSPI |
다음과 같이 pd.merge() 함수를 사용하여 merge를 진행 한다. 이로써 index 에 해당하는 정보를 얻을 수 있었다. 이번에는 이 ticker에 대한 정보를 가져오도록 하자.
index_code_info_2 = pd.merge(index_code_info, kor_index_list_df,
how = 'left',
on = 'index_code')
index_code_info_2.head()| ticker | index_code | index_code_nm | market |
|---|---|---|---|
| 005930 | 1001 | 코스피 | KOSPI |
| 373220 | 1001 | 코스피 | KOSPI |
| 000660 | 1001 | 코스피 | KOSPI |
| 207940 | 1001 | 코스피 | KOSPI |
| 006400 | 1001 | 코스피 | KOSPI |
ticker에 대한 정보를 가져 오기 위해서는 우선 지난 블로그에서 만들어 두었던 kor_ticker_list_df 를 불러와 보자.
kor_ticker_list_df = pd.read_csv(f'data_crawler/kor_ticker_list.csv')
kor_ticker_list_df.head()| ticker | corp_name | market |
|---|---|---|
| 095570 | AJ네트웍스 | KOSPI |
| 006840 | AK홀딩스 | KOSPI |
| 027410 | BGF | KOSPI |
| 282330 | BGF리테일 | KOSPI |
| 138930 | BNK금융지주 | KOSPI |
kor_ticker_list_df를 불러왔으면 이제 여기서 충돌을 피하기 위해 market를 제외한 나머지를 merge 해주도록 하자. 여기서는 ticker를 기준으로 merge를 진행 한다.
index_code_master = pd.merge(index_code_info_2, ticker_list_df[['ticker','corp_name']],
how = 'left',
on = 'ticker')
index_code_master.head()| ticker | index_code | index_code_nm | market | corp_name |
|---|---|---|---|---|
| 005930 | 1001 | 코스피 | KOSPI | 삼성전자 |
| 373220 | 1001 | 코스피 | KOSPI | LG에너지솔루션 |
| 000660 | 1001 | 코스피 | KOSPI | SK하이닉스 |
| 207940 | 1001 | 코스피 | KOSPI | 삼성바이오로직스 |
| 006400 | 1001 | 코스피 | KOSPI | 삼성SDI |
이렇게 생성된 index_code_master은 다음과 같이 저장해주고 마무리 하도록 하자.
index_code_master.to_csv(f'data_crawler/index_code_master.csv', index=False, mode='w')총평
이렇게 pykrx를 사용한 데이터 수집 Part2를 하면서 pykrx 부분은 마무리를 하게 되었다. 이제 미국주식을 수집하기 위해서 finance-datareader 관련 블로그를 남기면 데이터 수집 부분은 끝이 나게 된다.