파인튜닝을 통해 나만의 데이터를 학습 시켜 보자. 그전에 파인튜닝에 대해 알아 봐야 하는데, 아주 간단하게 알아보자. 파인튜닝에 대한 이론들은 아직도 많은 연구가 진행되고 있기 때문에 추후에 깊게 이론적인 내용에 대해 설명할 예정이다.
파인튜닝이란?
파인튜닝은 사전 훈련된 대규모 언어 모델(LLM)을 특정 작업이나 도메인에 맞게 미세 조정 하는 기법이다. LLM은 방대한 양의 텍스트 및 코드 데이터 세트로 사전 훈련되어 다양한 작업을 수행할 수 있는 기본적인 능력을 갖추고 있다. 그러나 특정 작업에 대한 성능을 최적화 하기 위해서는 추가 학습이 필요하다.
이게 무슨 뜻이냐?
쉽게 말해서 기본 LLM모델은 아직 전공이 없고 졸업을 앞둔 고3 수험생이라고 보면 된다. 그리고 이후에 성인이 되어서 각자에 맞는 전공을 학습하며 전문가가 되는데 이 과정을 파인튜닝이라고 이해하면 쉽다. 최근에 판례데이터를 파인튜닝하는 작업을 하고 있는데, 이 과정 역시 쉬운 길이 아니기도 해서 조금 더 진행해 볼 예정이다. 그럼 이제 부터 본격적으로 파인튜닝에 대해 알아보자.
준비물
파인튜닝은 많은 양의 GPU 자원을 소모 한다. 그렇기 때문에 GPU가 넉넉하게 들어간 PC가 있으면 좋다. Mac의 M1, M2에서도 파인튜닝이 가능하다는 글을 읽었는데, Mac이 없으니 구글의 코랩을 결재 해서 사용하자
- A100 수준의 GPU: Google Colab Pro 를 결재 하여 사용
- 학습을 위한 데이터: Huggingface 데이터셋 업로드 참고
참고
2023년 Llama2 이후로 상당히 파인튜닝에 대해 많은 글이 쏟아지고 있다. 그러다 2024년에 Llama3가 나오게 되면서 파인튜닝에 대해 여러 영상과 글을 읽어 봤는데 다음의 유튜브가 많은 참고가 되었다.
그럼 이제 이 유튜브를 참고하여 파인튜닝을 진행해보자. 이 모든 과정은 Google Colab에서 진행 한다.
파인튜닝
그럼 이제 본격적으로 파인튜닝에 대해 알아보자.
1. 라이브러리 설치
파인튜닝을 위해 다음의 라이브러리를 먼저 Colab에 설치 해주자. 각 라이브러리에 대한 설명은 다음과 같다.
- accelerate: PyTorch 모델의 학습 속도 향상과 추론 최적화를 위한 라이브러리
- peft: Parameter Efficient Fine Tuning의 약자로 대규모 언어 모델을 효율적으로 미세 조정할 수 있는 PEFT 기술 구현
- bitsandbytes: 모델 매개변수 양자화로 메모리 사용량 절감
- transformers: 다양한 자연어 처리 모델을 쉽게 사용할 수 있는 API 제공
- trl: Transformer Reinforcement Learning의 약자로 강화 학습 기반 언어 모델 미세 조정 기술 구현
- datasets: 자연어 처리 데이터셋 다운로드 및 전처리 지원
pip install -U accelerate==0.29.3 peft==0.10.0 bitsandbytes==0.43.1 transformers==4.40.1 trl==0.8.6 datasets==2.19.02. 라이브러리 로드
이제 파인튜닝에 필요한 라이브러리를 설치 해주자. 필요한 라이브러리의 설명은 다음과 같다.
- datasets: Hugging Face에서 제공하는 라이브러리로, 데이터셋을 쉽게 로드할 수 있다. (참고: huggingface 데이터셋 업로드)
- transformers: Hugging Face의 라이브러리로, 사전 학습된 트랜드포머 모델을 로드할 수 있다.
- AutoModelForCausalLM: 텍스트 생성 모델을 로드한다. 실제로 HuggingFace를 사용하여 모델을 로드 할때 자주 보게 될 라이브라리 이다.
- AutoTokenizer: 모델에 맞는 토크나이저를 로드한다. 이 역시 HuggingFace를 사용하게 되면 자주 보게될 함수 이다
- BitsAndBytesConfig: 모델을 양자화 하기 위한 설정을 제공한다. 양자화에 대한 이론적인 내용은 추후 작성할 예정
- TrainingArguments: 모델 학습을 위한 설정을 정의 한다.
- pipeline: 모델 추론을 위한 파이프라인을 생성한다.
- logging: 로깅
- peft: Parameter-Efficient Fine-Tuning 의 약자로 파인튜닝에 있어 경량화를 위한 이론적인 내용이다. 파인튜닝에 대해 공부하게 된다면 앞으로 자주 보게 될 내용이다.
- LoraConfig: LoRA(Low-Rank Adaptation) 설정을 정의 하며 peft와 함께 파인튜잉에 대해 공부하게 되면 자주 보게될 내용이다.
- trl: Transformer Reinforcement Learning의 약자로 트랜스포머 모델에 강화 학습을 적용할 수 있다.
- SFTTrainer: Supervised Fine-Tuning을 지원하는 트레이너 라이브러리 이다.
그리고 Huggingface API키를 입력하기 위한 라이브러리르 호출해 준다. 이 내용은 직전의 블로그들을 참고한다.
import os
import torch
from datasets import load_dataset
from transformers import (
AutoModelForCausalLM,
AutoTokenizer,
BitsAndBytesConfig,
TrainingArguments,
pipeline,
logging,
)
from peft import LoraConfig
from trl import SFTTrainer
import huggingface_hub
huggingface_hub.login('Huggingface API KEY')3. Model/dataset 설정
우선 Model과 dataset을 설정하자. 파인튜닝을 하기 위해선 기본 LLM 모델이 필요한데, Llama3는 영어에 특화되어 있고 한국어에는 약간 취약하다. 그래서 국내의 많은 사람, 기업들이 Llama3를 한국어로 파인튜닝해서 제공 해주고 있다. 그중에 자주 참고 하는 파인튜닝 모델은 다음의 teddylee, beomi님이기 때문에 두분의 모델을 남겨 두고 이 중에서 각각 최신, 최고의 성능을 내는 모델을 찾아서 넣어주면 된다.
# Hugging Face Basic Model 한국어 모델
# base_model = "teddylee777/Llama-3-Open-Ko-8B-gguf" # 테디님의 Llama3 한국어 파인튜닝 모델
base_model = "beomi/Llama-3-Open-Ko-8B" # beomi님의 Llama3 한국어 파인튜닝 모델
# 주가 증권 보고서 gemini 데이터셋
hkcode_dataset = "uiyong/gemini_result_kospi_0517_jsonl"
# 새로운 모델 이름
new_model = "Llama3-owen-Ko-3-8B-kospi"4. GPU 환경 확인 및 attention 메커니즘 설정
파인튜닝은 높은 수준의 GPU 연산을 필요로 한다. 다음의 코드는 GPU환경에 따라 최적의 메커니즘을 설정 하는 과정이다.
고성능 GPU
torch.cuda.get_device_capability()[0] >= 8조건문을 통해 현재 사용중인 GPU의 CUDA 연산 능력을 확인한다. 8이상이면 고성능 GPU 로 판단한다.- Attention 메커니즘 선택: 고성능 Attention인 flash attention 2 을 사용해준다.
- 데이터 타입을 bfloat16으로 설정해준다. bfloat16은 메모리 사용량을 줄이면서도 계산의 정확성을 유지할 수 있는 데이터 타입이다.
if torch.cuda.get_device_capability()[0] >= 8:
!pip install -qqq flash-attn
attn_implementation = "flash_attention_2"
torch_dtype = torch.bfloat16
else:
attn_implementation = "eager"
torch_dtype = torch.float165. QLoRA를 사용한 4비트 양자화 설정
이번에는 QLoRA를 사용해서 양자화를 해보자. 허깅페이스의 BitsAndBytesConfig()를 사용하며 각각의 옵션에 대한 내용은 다음과 같다.
- load_in_4bit=True : 모델 가중치를 4비트로 로드
- bnb_4bit_quant_type=“nf4”: 양자화 유형으로는 “nf4”를 사용한다.
- bnb_4bit_compute_dtype=torch_dtype: 양자화를 위한 컴퓨팅 타입은 직전에 정의 했던
torch_dtype으로 지정 해준다. - bnb_4bit_use_double_quant=False: 이중 양자화는 사용하지 않는다.
# QLoRA config
quant_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch_dtype,
bnb_4bit_use_double_quant=False,
)6. 데이터 로드 및 모델 설정
모델 로드
이제 HuggingFace에서 사전학습된 모델을 불러오자. AutoModelForCausalLM.from_pretrained() 함수를 사용하여 사전 학습된 모델을 불러온다. 코드에 대한 설명은 다음과 같다.
- AutoModelForCausalLM.from_pretrained()
- 모델명은 base_model = “beomi/Llama-3-Open-Ko-8B”
- quantization_config=quant_config: 앞서 정의한 양자화 설정을 가져온다. quant_config는 직전 코드에서 정의했던 BitsAndBytesConfig() 이다.
- device_map={““: 0}: 모델을 특정 장치에 할장한다. 여기서
{"": 0}는 모델을 첫 번재 GPU에 할당 하겠다는 의미.
모델 설정
- model.config.use_cache = False: 모델의 캐시 기능을 비활성화 한다. 캐시는 이전 계산 결과를 저장하기 때문에 추론 속도를 높이는 역할을 한다. 그러나 메모리 사용량을 증가시킬 수 있기 때문에, 메모리부족 문제가 발생하지 않도록 하기 위해 비활성화 해주는 것이 좋다.
- model.config.pretraining_tp = 1: 모델의 텐서 병렬화(Tensor Parallelism) 설정을 1로 지정한다. 설정값 1은 단일 GPU에서 실행되도록 설정 해주는 의미 이다.
# llama 데이터 로드
dataset = load_dataset(hkcode_dataset, split="train")
# 데이터 확인
print( dataset[5] )### 모델 로드
model = AutoModelForCausalLM.from_pretrained(
base_model,
quantization_config=quant_config,
device_map={"": 0}
)
model.config.use_cache = False
model.config.pretraining_tp = 1실행하면 다음과 같이 모델들을 불러오게 된다. 시간은 약 3분정도 소요 된다.
config.json: 100% ████████████████ 698/698 [00:00<00:00, 61.0kB/s]
model.safetensors.index.json: 100% ████████████████ 23.9k/23.9k [00:00<00:00, 1.50MB/s]
Downloading shards: 100% ████████████████ 6/6 [01:28<00:00, 13.09s/it]
model-00001-of-00006.safetensors: 100% ████████████████ 3.00G/3.00G [00:15<00:00, 202MB/s]
model-00002-of-00006.safetensors: 100% ████████████████ 2.94G/2.94G [00:15<00:00, 132MB/s]
model-00003-of-00006.safetensors: 100% ████████████████ 2.97G/2.97G [00:15<00:00, 201MB/s]
model-00004-of-00006.safetensors: 100% ████████████████ 2.94G/2.94G [00:17<00:00, 214MB/s]
model-00005-of-00006.safetensors: 100% ████████████████ 2.94G/2.94G [00:15<00:00, 221MB/s]
model-00006-of-00006.safetensors: 100% ████████████████ 1.29G/1.29G [00:05<00:00, 237MB/s]
Loading checkpoint shards: 100% ████████████████ 6/6 [00:10<00:00, 1.51s/it]
generation_config.json: 100% ████████████████ 132/132 [00:00<00:00, 11.8kB/s]7. 토크나이저 로드
이번에는 사전 학습된 모델과 함께 사용할 토크나이저를 로드 하자. 토크나이저는 텍스트를 모델이 이해할 수 있는 형식으로 변환 하는 역할을 한다. AutoTokenizer.from_pretrained() 함수를 사용하며, 각 코드에 대한 설명은 다음과 같다.
- 모델명은 base_model = “beomi/Llama-3-Open-Ko-8B”
- trust_remote_code=True: 원격 코드의 신뢰 여부 설정. True로 설정하여 HuggingFace hub에서 제공하는 사용자 정의된 토크나이저 코드를 신뢰 하고 실행한다.
- tokenizer.pad_token = tokenizer.eos_token: 캐딩 토큰으로 eos_token을 사용한다. 즉, 시퀀스 길이를 맞추기 위해 문장 끝에 eos_token를 사용한다.
- tokenizer.pad_token: 패딩 토큰을 설정한다. 패딩토큰은 입력 시퀀스를 동일한 길이로 맞추기 위해 사용된다.
- tokenizer.eos_token: 문장의 끝(End Of Sentence)을 나타내는 토큰이다.
- tokenizer.padding_side = “right”: 패딩 토큰을 시퀀스의 어느 쪽에 추가할지 설정 한다.
# 토크나이저 로드
tokenizer = AutoTokenizer.from_pretrained(
base_model,
trust_remote_code=True)
tokenizer.pad_token = tokenizer.eos_token
tokenizer.padding_side = "right"tokenizer_config.json: 100% ████████████████ 51.0k/51.0k [00:00<00:00, 4.32MB/s]
tokenizer.json: 100% ████████████████ 9.09M/9.09M [00:00<00:00, 39.2MB/s]
special_tokens_map.json: 100% ████████████████ 301/301 [00:00<00:00, 24.6kB/s]
Special tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tuned or trained.8. Peft 파라미터 설정
이번에는 Peft 파라미터를 설정해주자. Peft 기법중 하나인 LoRA(Low-Rank Adaptation)를 사용하여 언어 모델을 효율적으로 미세 조정하기 위한 설정 하기 위함이다.
LoRA란?
LoRA는 대규모 언어 모델을 미세 조정할 때 모델 전체의 가중치를 변경하는 대신, 작은 크기의 어댑터 행렬을 추가 하여 학습하는 방법이다. 이를 통해 학습해야 할 파라미터수를 줄여 학습 속도를 높이고 메모리 사용량을 줄일 수 있다. 이렇게 하면 메모리 요구량과 계산 비용을 크게 절감할 수 있다.
peftpeft라이브러리의 LoraConfig()를 사용하며, 이제 코드에 대해 알아보자.
- lora_alpha=16: LoRA의 스케일링 계수를 설정 한다. 값이 클 수록 학습 속도가 빨라질 수 있지만, 너무 크게 되면 모델이 불안정해질 수 있다.
- lora_dropout=0.1: 과적합을 방지하기 위한 드롭아웃 확률을 설정한다. 여기서는 10%(0.1)의 드롭아웃 확률을 사용하여 모델의 일반화 성능을 향상시킨다.
- r=64: LoRA 어댑터 행렬의 Rank를 나타낸다. 랭크가 높을수록 모델의 표현 능력은 향상되지만, 메모리 사용량과 학습 시간이 증가한다. 일반적으로 4, 8, 16, 32, 64 등의 값을 사용한다.
- bias=“none”: LoRA 어댑터 행렬에 대한 편향을 추가할지 여부를 결정한다. “none”옵션을 사용하여 편향을 사용하지 않는다.
- task_type=“CAUSAL_LM”: LoRA가 적용될 작업 유형을 설정한다. CAUSAL_LM은 Causal Language Modeling 작업을 의미한다. 이는 특히 GPT 같은 텍스트 생성 모델에 주로 사용된다.
peft_params = LoraConfig(
lora_alpha=16,
lora_dropout=0.1,
r=64,
bias="none",
task_type="CAUSAL_LM",
)9. 학습 모델 설정
Huggingface의 Transformers 라이브러리의 TrainingArguments() 를 사용하여 모델 학습 과정에 필요한 다양한 설정값을 정의하자. 각 매개변수는 학습 성능과 효율정을 조절한다. 각 코드에 대해 알아보자.
- output_dir=“./results”: 학습 결과를 저장할 디렉토리를 지정한다. 여기에 모델 가중치, 로그, 체크포인트 등이 저장된다.
- num_train_epochs=10: 전체 학습 데이터 셋 반복횟수를 설정한다. 10으로 설정 해주었다. (기본값은 3이다.)
- per_device_train_batch_size=4: 각 GPU 또는 CPU에서 사용할 배치 크기를 설정한다. 여기서는 4로 설정을 해주었다. 때문에, 각 디바이스에서 한 번에 4개의 샘플을 처리한다. (기본값은 8이다.)
- gradient_accumulation_steps=1: 여러 배치에서 계산된 그래디언트를 누적하여 실제 가중치 업데이트를 수행할 빈도를 지정한다. 이는 GPU 메모리가 부족할 때 유용하다. (기본값은 1이다.)
- optim=“paged_adamw_32bit”: 사용할 옵티마이저를 지정한다. paged_adamw_32bit은 AdamW옵티마이저의 변형으로, 32비트 정밀도를 사용한다. (기본값은 adamw_hf이다.)
- save_steps=25: 25스텝마다 모델을 기록하고 저장한다. (기본값은 500이다.)
- logging_steps=25: 25스텝마다 로그를 기록하고 저장한다. (기본값은 500이다.)
- learning_rate=2e-4: 학습률을 설정한다. 학습률은 모델이 가중치를 업데이트 하는 속도를 결정한다. 여기서는 0.0002로 설정 해주었다. (기본값은 5e-5이다.)
- weight_decay=0.001: 가중치 감소 계수를 설정 해준다. 이는 모델의 복잡도를 줄여 과적합을 방지하는 정규화 기법이다. (기본값은 0이다.)
- fp16=False: half-precision의 약자로 16비트 부동소수점(FP16) 정밀도를 사용할지 여부를 설정한다. GPU 메모리 사용량을 줄이고 학습 속도를 높이는 데 도움이 될 수 있지만, 모든 모델에 적용 가능한것은 아니며 여기서는 False로 지정해주었다.
- bf16=False: Brain Floating의 약자로 BF16연산을 사용할지 여부를 지정한다.
- max_grad_norm=0.3: 그레디언트의 최대 Norm을 설정한다. 그레디언트의 폭발을 방지하기위한 값이다.
- max_steps=-1: 최대 학습 스텝 수를 지정한다. -1로 설정 하면 num_train_epochs동안만 학습을 진행한다.
- warmup_ratio=0.03: 학습률 워밍엄에 사용할 스텝 비율을 설정한다. 워밍업 기간 동안 학습률을 점진적으로 증가시켜 모델이 안정적으로 학습을 시작할 수 있게 도와준다.
- group_by_length=True: 입력 시퀀스의 길이에 따라 배치를 그룹화 할지를 설정한다. 길이가 비슷한 샘플을 함께 배치하면 패딩의 양을 줄이기 때문에 메모리 사용을 최적화할 수 있다.
- lr_scheduler_type=“constant”: 학습률 스케쥴러 유형을 설정한다. constant로 하여 일정하게 유지되게 설정 해주었다.
- report_to=“tensorboard”: 학습 로그를 기록할 툴을 지정한다. 여기서는 tensorboard를 사용해주었다.
training_params = TrainingArguments(
output_dir="./results",
num_train_epochs=10,
per_device_train_batch_size=4,
gradient_accumulation_steps=1,
optim="paged_adamw_32bit",
save_steps=25,
logging_steps=25,
learning_rate=2e-4,
weight_decay=0.001,
fp16=False,
bf16=False,
max_grad_norm=0.3,
max_steps=-1,
warmup_ratio=0.03,
group_by_length=True,
lr_scheduler_type="constant",
report_to="tensorboard"
)10. 모델 학습
trl 라이브러리의 SFTTrainer클래스의 인스턴스인 trainer 객체를 사용하여 모델 학습을 시작하자. trainer.train()는 직전에 정의했던 TrainingArguments와 함께 설정된 모든 매개변수를 사용하여 모델을 학습시킨다.
# 파인튜닝
trainer = SFTTrainer(
model=model,
train_dataset=dataset,
peft_config=peft_params,
dataset_text_field="text",
max_seq_length=None,
tokenizer=tokenizer,
args=training_params,
packing=False,
)trainer.train()[580/580 13:21, Epoch 10/10]
Step Training Loss
25 1.649800
50 0.940300
75 0.776500
..
..
..
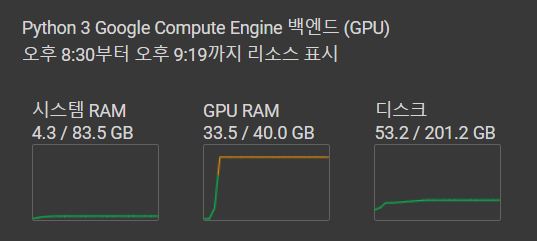
TrainOutput(global_step=580, training_loss=0.4969192005436996, metrics={'train_runtime': 806.1079, 'train_samples_per_second': 2.853, 'train_steps_per_second': 0.72, 'total_flos': 1.6389467875786752e+16, 'train_loss': 0.4969192005436996, 'epoch': 10.0})학습을 하게 되면 다음과 같이 고성능 GPU중 하나인 A100기준으로 아주 많은 메모리를 사용하게 된다.
모델 테스트
이렇게 모델이 테스트가 끝났으면, 결과를 한번 알아보자. 이는 Gemini로 만든 증권 보고서를 기반으로 파인튜닝을 토대로 나온 결과이다.
logging.set_verbosity(logging.CRITICAL)
prompt = "삼성전자의 5월 17일 증권 현황은 어떤가요?"
pipe = pipeline(task="text-generation", model=model, tokenizer=tokenizer, max_length=200)
result = pipe(f"<s>[INST] {prompt} [/INST]")
print(result[0]['generated_text'])**종목 정보**
* 종목명: 삼성전자
* 날짜: 2022년 5월 17일
**매수/매도 신호**
* 삼성전자는 정배열 매수 신호를 보였습니다.
* 전기전자 업종 지수는 정배열 매수 신호를 보였습니다.
* 제조업 업종 지수는 정배열 매수 신호를 보였습니다.HuggingFace에 모델/토크나이저 적재
파인튜닝도 했고 결과를 확인했으니 이제 이 모델을 HuggingFace에 적제 하자. 지난번 데이터셋 적재와 같이 push_to_hub()함수를 사용하면 된다. 그 결과 다음의 링크를 확인해보면 HuggingFace에 모델이 성공적으로 적재된것을 확인할 수 있다.
model.push_to_hub("uiyong/kospi_report_model_0517")
tokenizer.push_to_hub("uiyong/kospi_report_model_0517")총평
이번에는 파인튜닝에 대해 알아보았다. 작년 12월 부터 랭체인부터 시작해서 LLM에 흥미를 갖게 되었다. 랭체인을 통해 RAG에 처음 흥미를 가졌을때는 모든 법률 데이터 역시 쉽게 될줄 알았었다. 그러나 데이터의 양이 많아 지게 되면 RAG로는 한계가 있음을 깨닫고 그때부터 파인튜닝에 대해 알아보게 되었는데 2024년 5월 말이 되어서야 블로그를 쓰게 된다.